About Project
- 기간: 23.09.06 ~ 23.12.20
- 팀 인원: 4명
- 내 역할: 프로젝트 제안, 서버 설계 · 구현 · 테스트
- 기여도: 25%
Background
go-transistor는 채팅 앱을 위해 개발된 메시징 서비스 프레임워크이다.
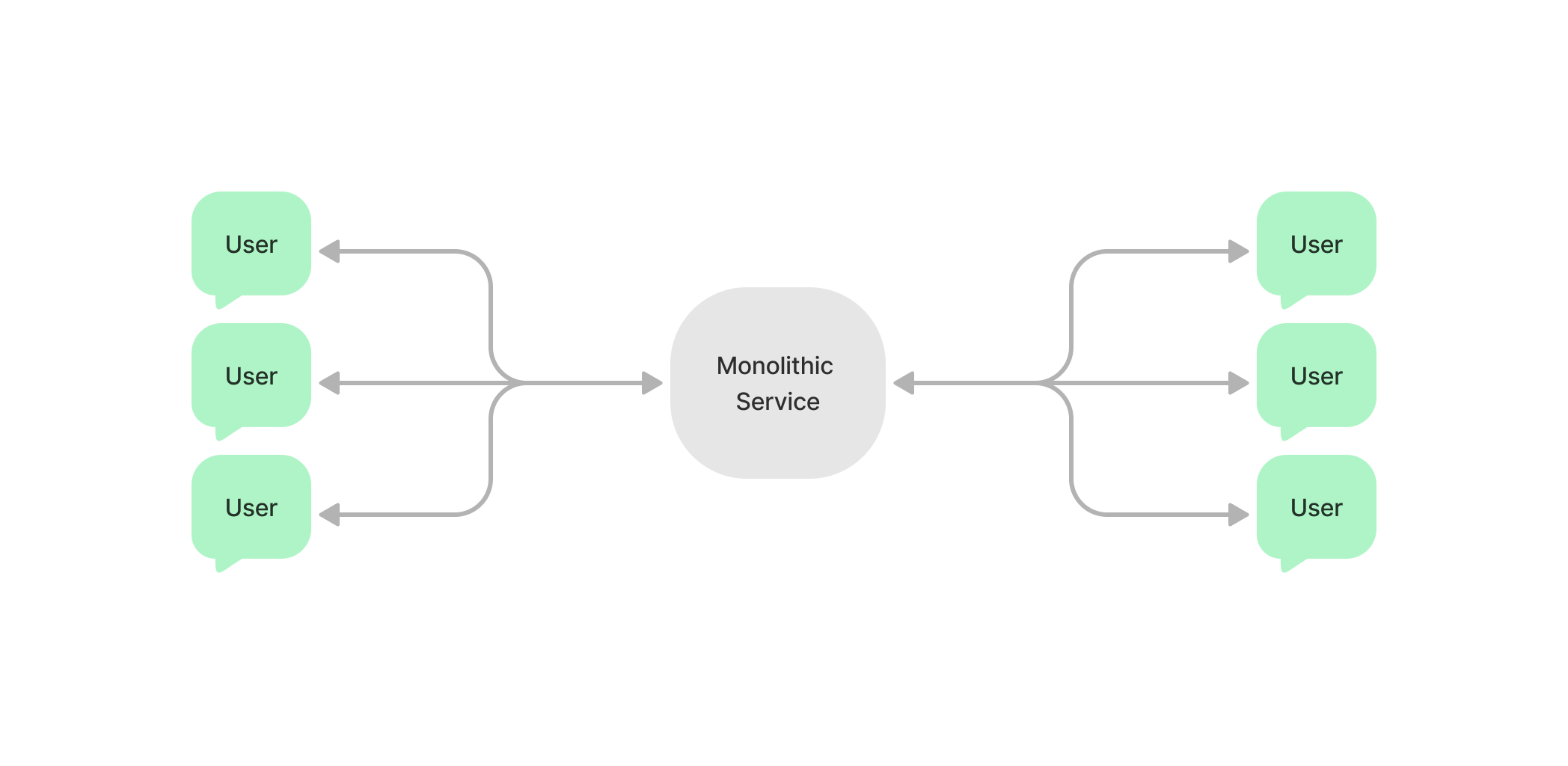 모놀리식 서버는 접속된 모든 유저의 정보를 런타임 메모리에 유지할 수 있기 때문에 쉽게 채팅 앱을 구현할 수 있다.
모놀리식 서버는 접속된 모든 유저의 정보를 런타임 메모리에 유지할 수 있기 때문에 쉽게 채팅 앱을 구현할 수 있다.
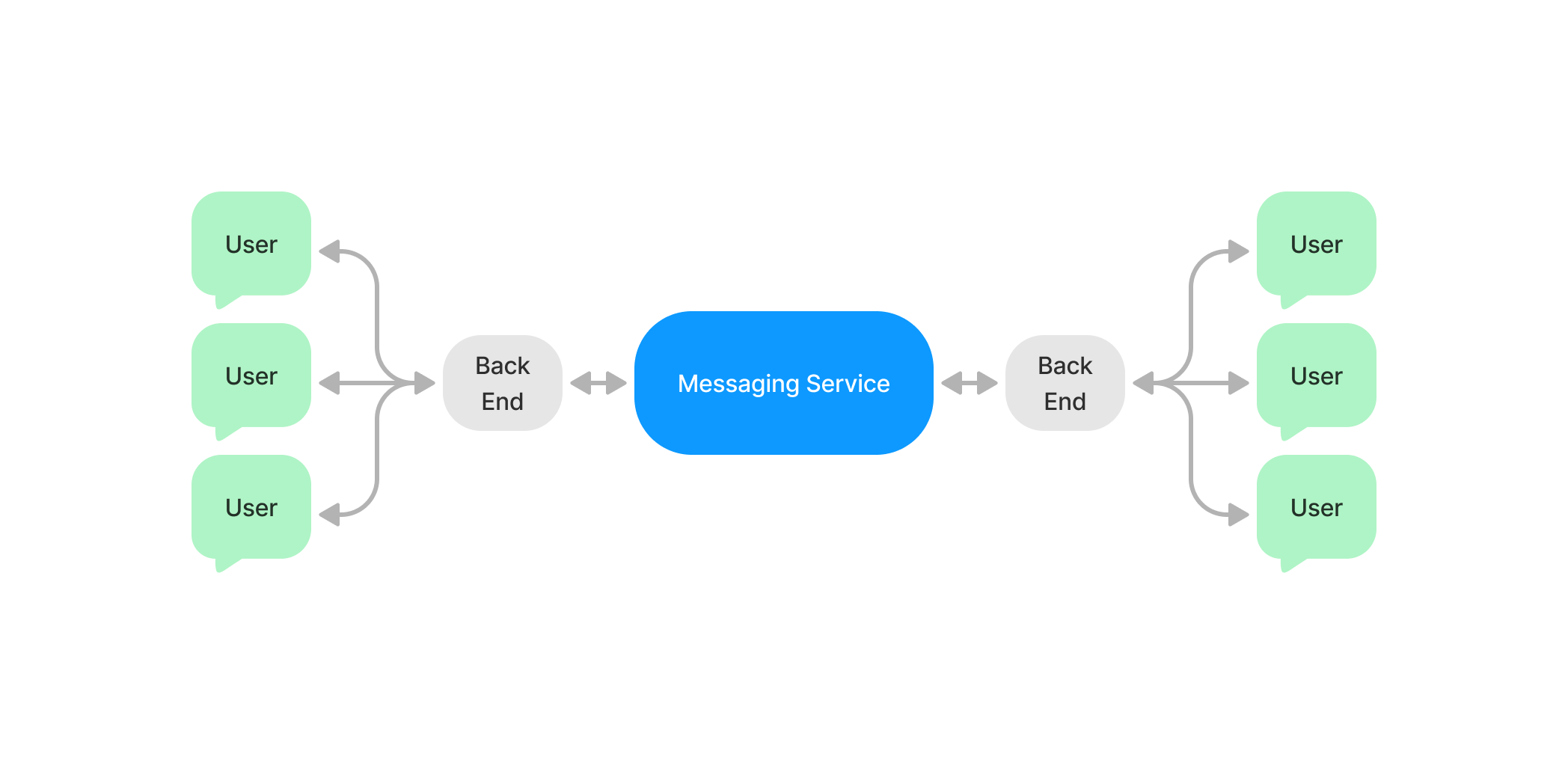 마이크로서비스에서는 연결된 유저 정보가 각 서버의 런타임 메모리에 분산되어있기 때문에 전체 아키텍처에서 이 정보를 매개해주는 서비스 (메시징 서비스)가 필요하다.
마이크로서비스에서는 연결된 유저 정보가 각 서버의 런타임 메모리에 분산되어있기 때문에 전체 아키텍처에서 이 정보를 매개해주는 서비스 (메시징 서비스)가 필요하다.
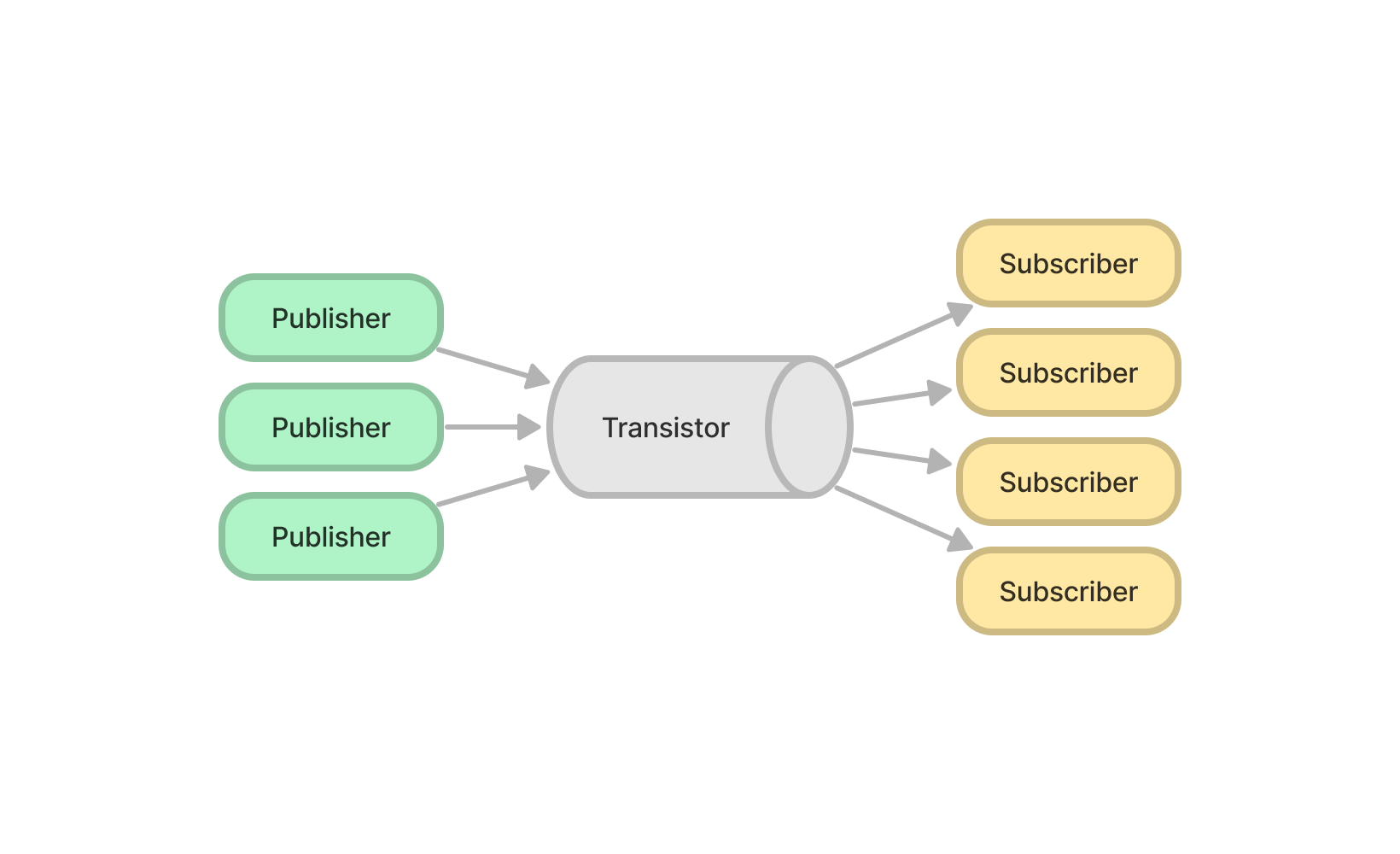
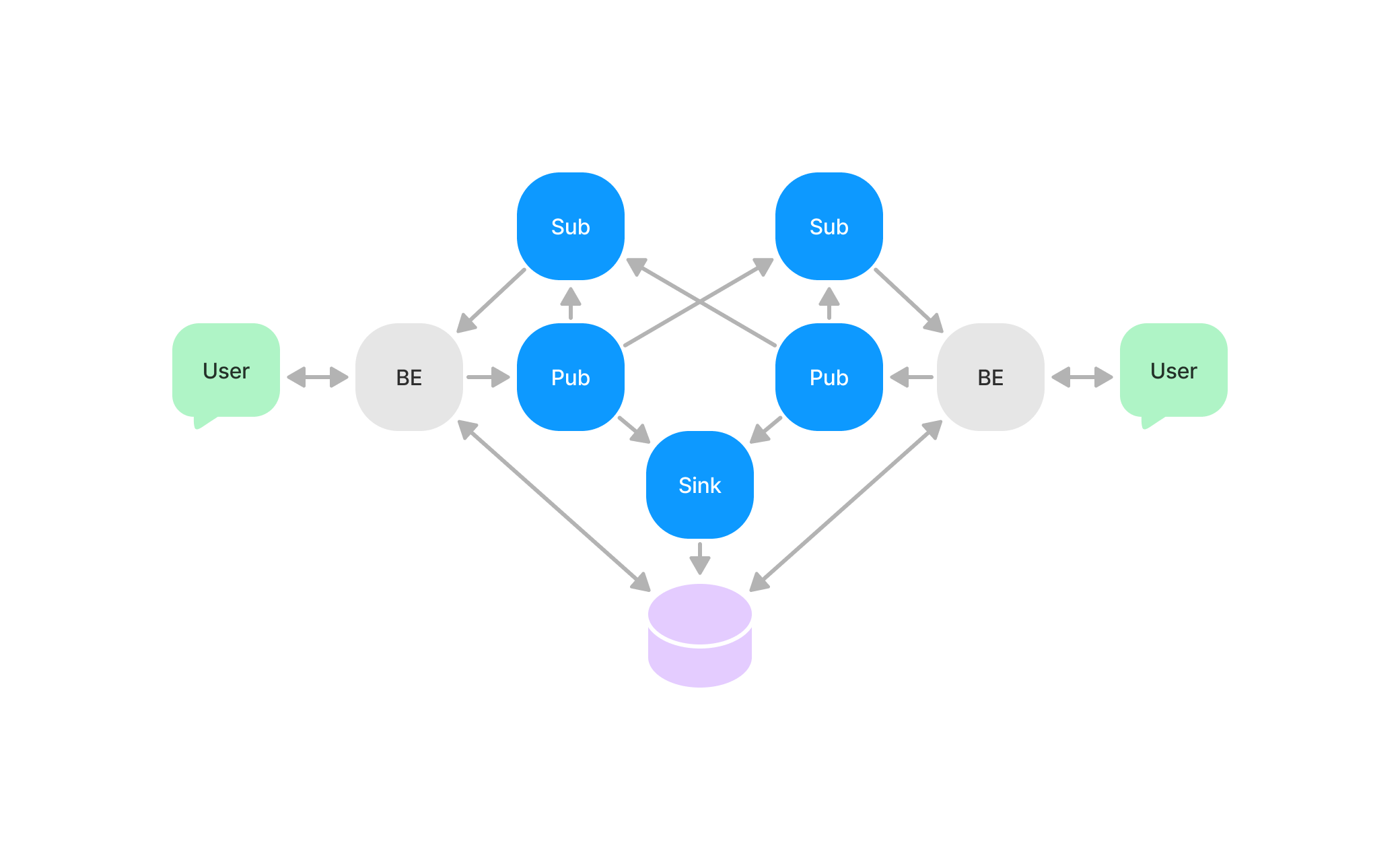 또한 이 메시징 서비스는 다시 분산 시스템으로 구현할 수 있다. 분산 시스템 구현을 위해 채팅 앱에서 필요한 메시징 서비스의 역할을 구분해보면 다음과 같다:
또한 이 메시징 서비스는 다시 분산 시스템으로 구현할 수 있다. 분산 시스템 구현을 위해 채팅 앱에서 필요한 메시징 서비스의 역할을 구분해보면 다음과 같다:
- Publisher: 새로운 메시지를 게시
- Subscriber: 필요한 메시지를 구독
- Sink: DB에 저장
다이어그램은 복잡해보이지만 이 노드들은 공통점이 있다:
- Publisher: 새로운 메시지를 받아서 다른 노드에 전달한다.
- Subscriber: Pub 노드로부터 메시지를 받아서 BE에 전달한다.
- Sink: Pub 노드로부터 메시지를 받아서 DB에 입력한다.
따라서 네트워크 상에서 메시지를 송수신하는 인터페이스를 구현하면 노드마다 다른 기능은 이 인터페이스를 확장해서 해결할 수 있다.
Transistor is a Pattern
트랜지스터라는 이름은 전자부품의 “트랜지스터"에서 가져왔다. 트랜지스터가 수행하는 메시지를 받고 전달하는 역할이 실제 트랜지스터와 유사해 보이기 때문이다.
트랜지스터는 인터페이스, 혹은 클래스로서 구현되었다. 여기에 특별한 확장 기능이 없는 경우, 트랜지스터는 서버 프로그램 자체를 의미할 수도 있다. 그러나 추상적으로 생각해보면 트랜지스터는 일종의 패턴(프레임워크)으로 이해할 수 있다. 트랜지스터는 다음의 목표를 수행하기위한 문제 해결 패턴이다.
트랜지스터의 목표: Publisher로부터 메시지를 수신하고, 메시지를 토픽에 따라 분류하고, 토픽을 구독하는 Subscriber로 메시지를 전달한다.
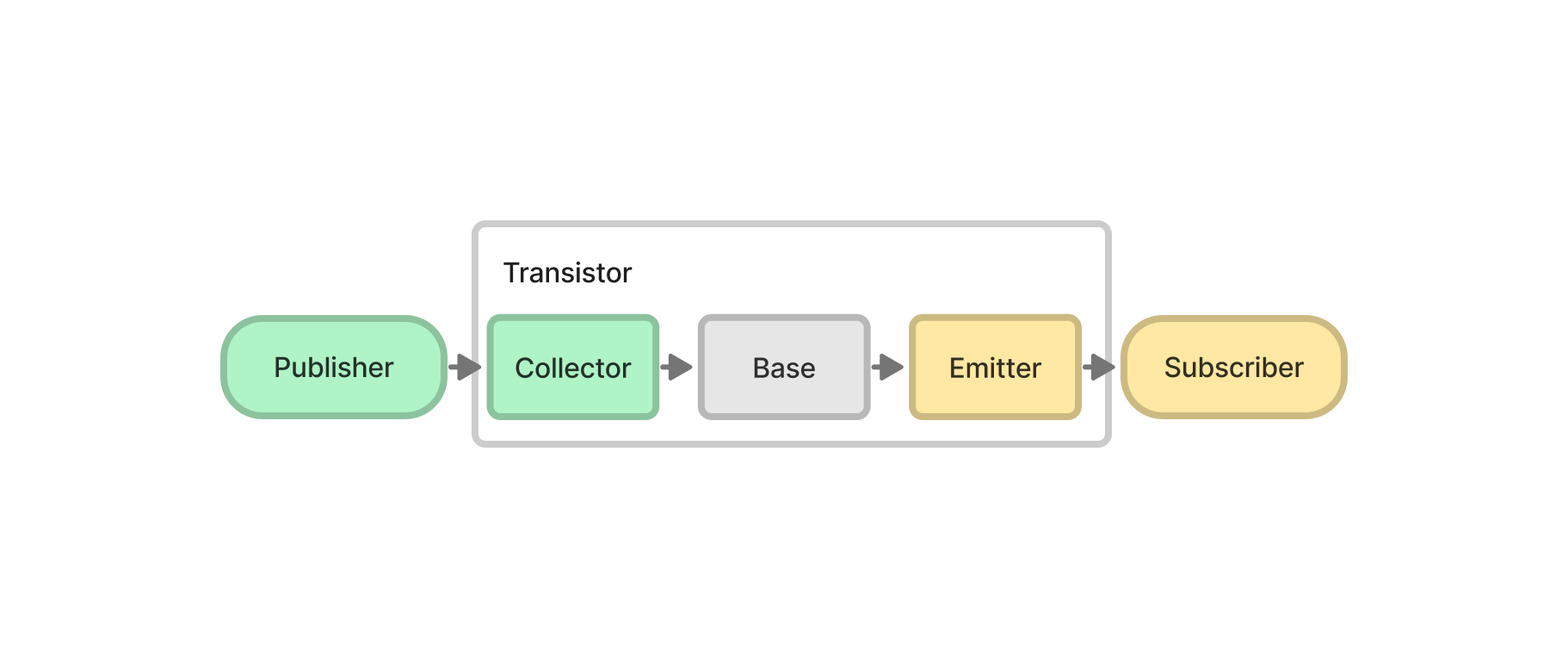 트랜지스터의 구성 요소는 다음과 같다:
트랜지스터의 구성 요소는 다음과 같다:
- Collector: Publisher로부터 받은 메시지를 Base를 통해 Subscriber로 전달
- Base: Subscriber들의 토픽 구독 상태 관리
- Emitter: 전달받은 메시지를 메모리 큐에 저장하고, Subscriber로 전송
트랜지스터의 추상적인 모습에서 한단계 더 들어가보자.
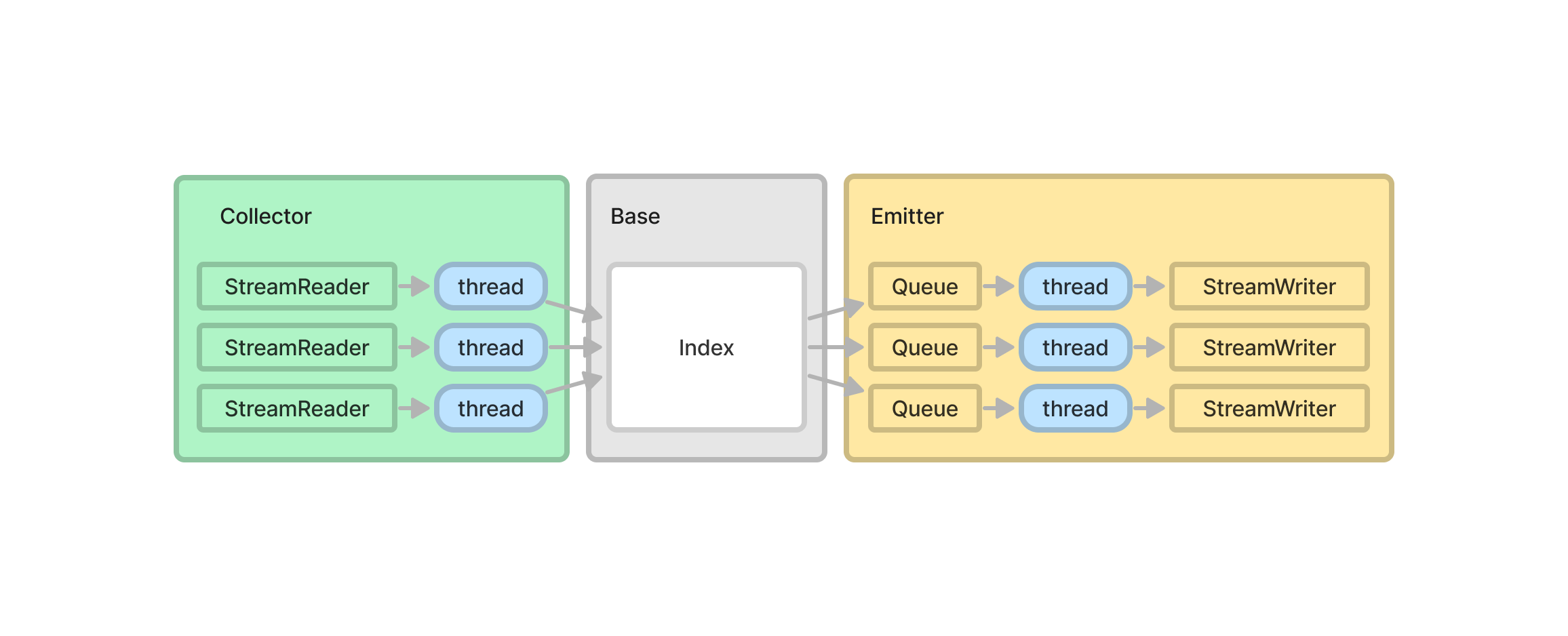
StreamReader/StreamWriter: 메시지를 읽는/쓰는 추상화된 네트워크 인터페이스thread: 스레드가 할당되어 동작하는 위치Index: 메시지의 토픽을 key로, 해당 토픽을 구독하는 Subscriber 집합을 value로 저장하는 상태 관리자 클래스Queue: 네트워크 I/O는 지연시간이 발생하기 때문에 비동기 처리를 위해 메시지를 메모리에 임시로 저장하는 곳
여기서 Collector, Base, Emitter 클래스는 내부의 구성 요소를 추가하고 삭제하는 역할로 이해할 수 있다.
Base and Index Optimization
Collector와 Emitter는 내부 리스트에 스트림을 추가하고 스레드를 할당하는 단순한 역할을 수행하지만 Base와 Index는 그보다 더 복잡한 역할을 수행한다.
Index
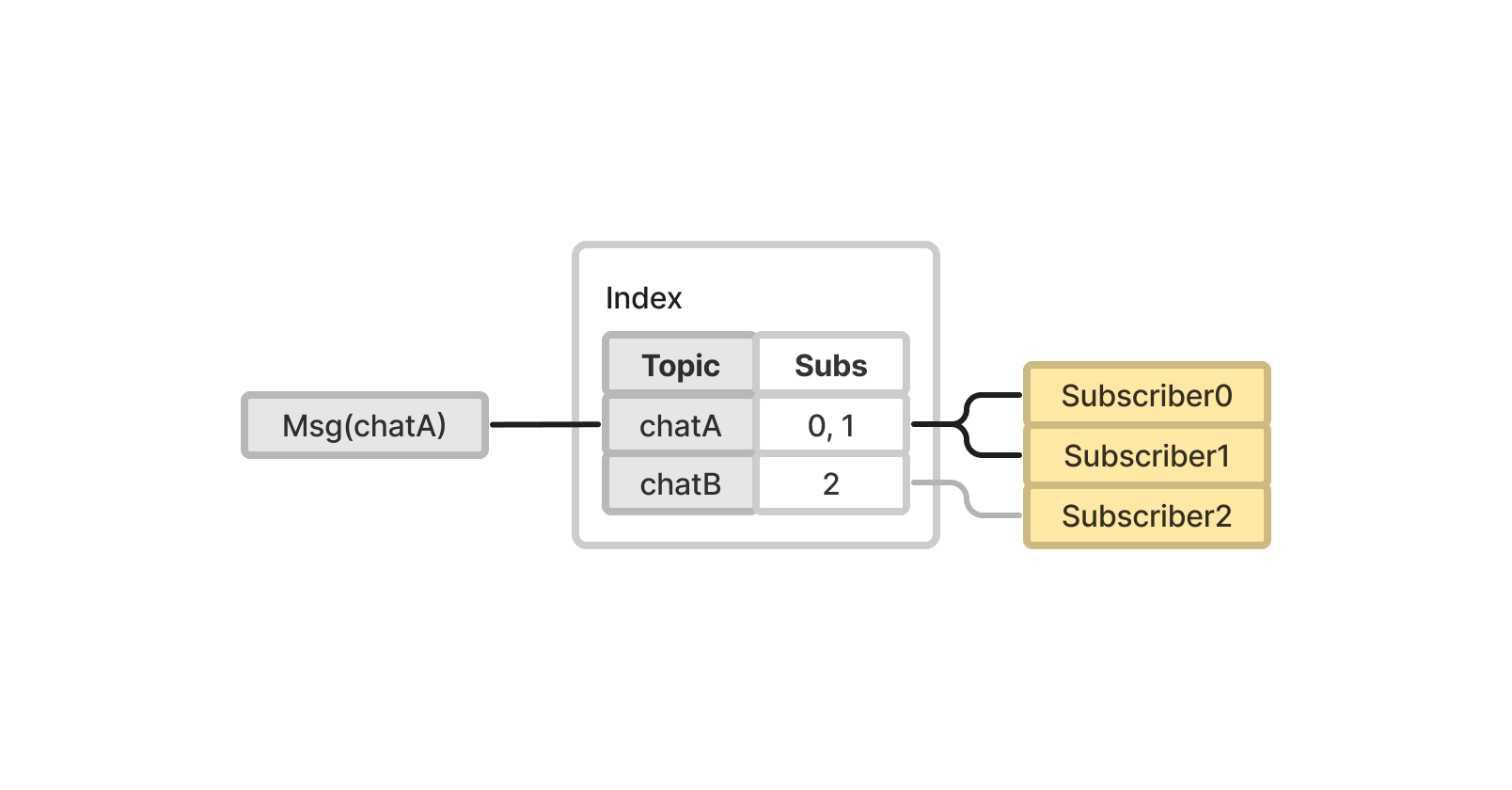 인덱스는 토픽을 Key로, 해당 토픽을 구독하는 Subscriber 집합을 Value로 저장하기 때문에 Dictionary 구조로 쉽게 해결할 수 있다.
인덱스는 토픽을 Key로, 해당 토픽을 구독하는 Subscriber 집합을 Value로 저장하기 때문에 Dictionary 구조로 쉽게 해결할 수 있다.
그러나 스트링 타입 토픽은 실제로 사용할 때 제약이 많다. 예를 들어 토픽에서 채팅방 코드를 구분하려면 스트링의 특정 위치에서(여기서는 prefix) 채팅방 코드를 추출하는 일반식 탐색을 실행해야한다.
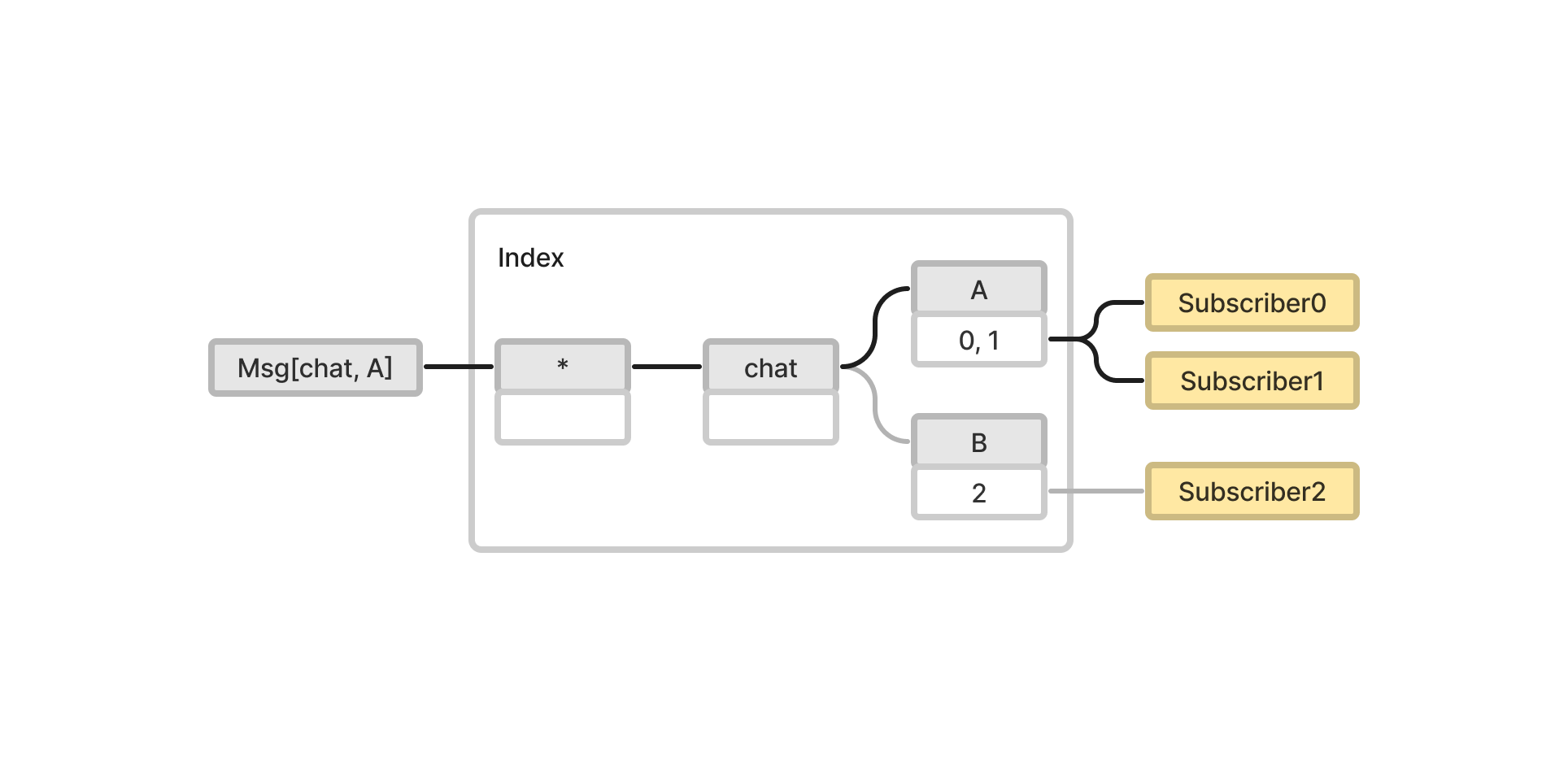 해결 방법은 토픽을 스트링 리스트 타입으로 구현하면 된다. 그렇다면 인덱스 자료 구조는 트리가 된다.
해결 방법은 토픽을 스트링 리스트 타입으로 구현하면 된다. 그렇다면 인덱스 자료 구조는 트리가 된다.
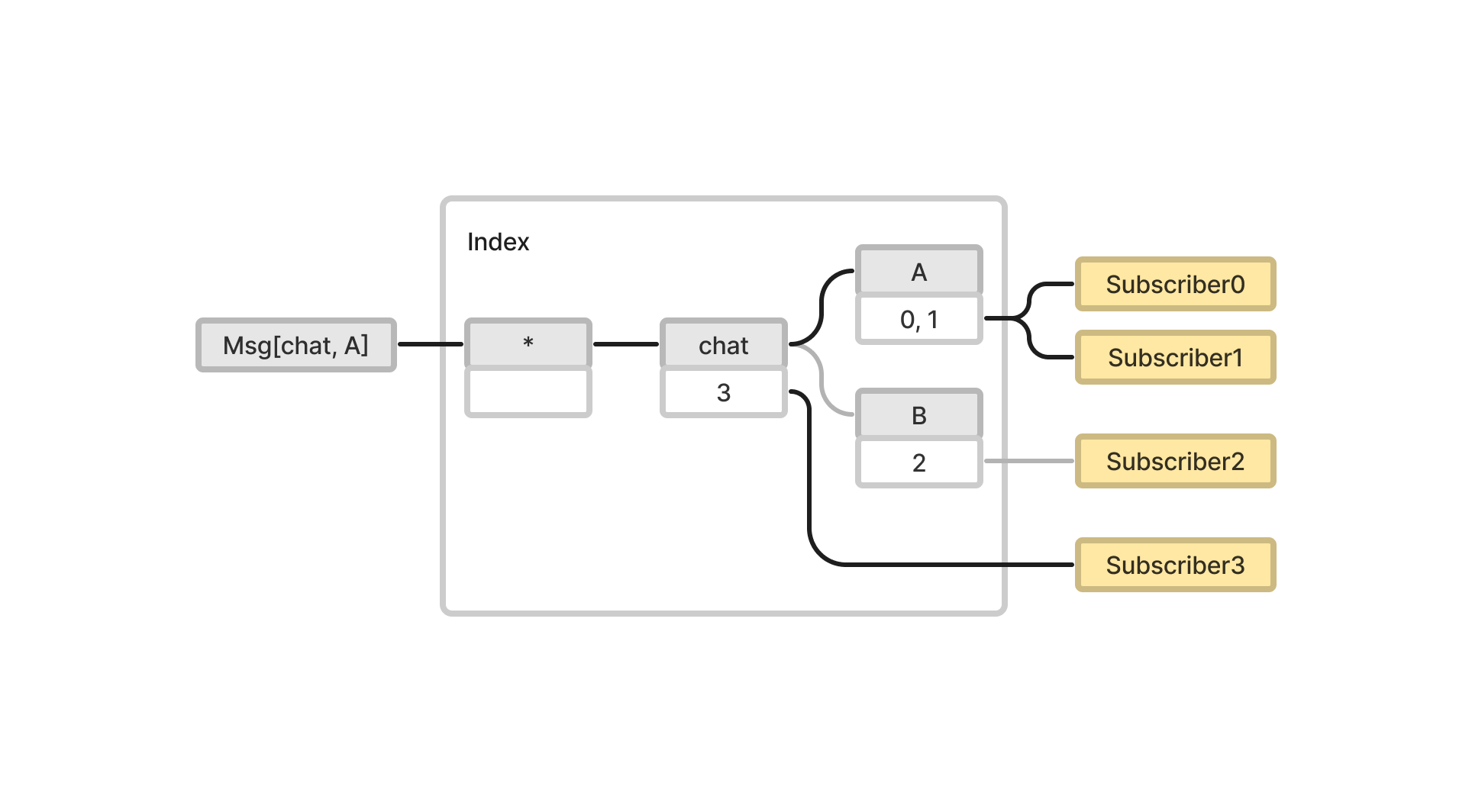 트리 구조의 장점은 계층 표현이 가능하다는 것이다. 예를 들어
트리 구조의 장점은 계층 표현이 가능하다는 것이다. 예를 들어 chat에 구독하고 있는 Subscriber3는 토픽이 chat으로 시작하는 모든 메시지를 받는다.
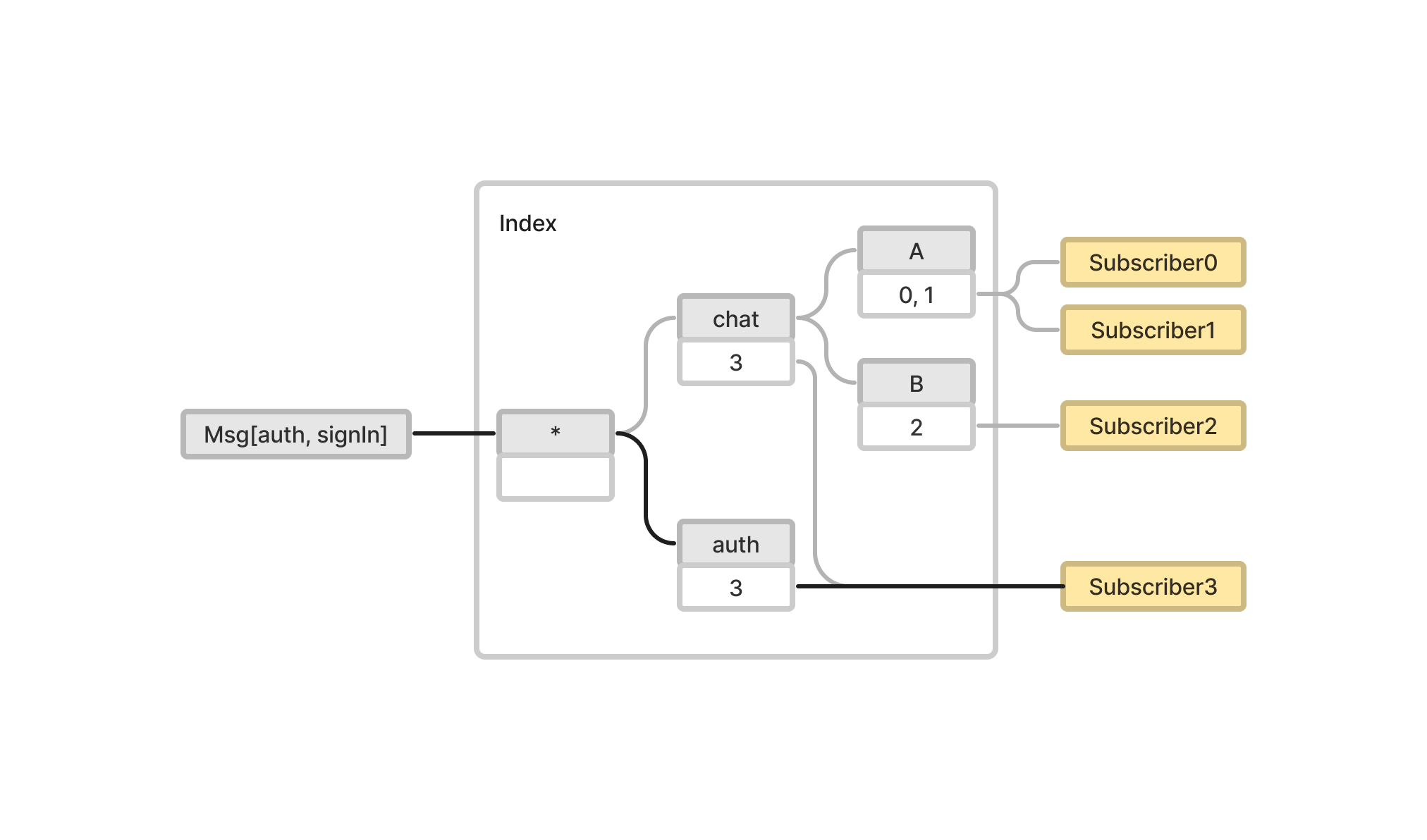 또한 여러 상위 토픽 계층이 있을 경우 개발자에게 더 직관적이다. 이 다이어그램에서는 Subscriber3가
또한 여러 상위 토픽 계층이 있을 경우 개발자에게 더 직관적이다. 이 다이어그램에서는 Subscriber3가 chat과 auth에 구독한 상태를 나타낸다.
문제는 구현 방법이다. Subscription을 추가하고 제거할 경우, 그리고 메시지를 전달할 경우 어떤 알고리즘을 사용해야할까? 핵심은 다음과 같다.
- 구독 규칙: 같은 Subscriber에 대해 상위 토픽에 구독이 존재할 경우 하위 토픽에 구독할 수 없다.
- 전송 규칙: 어떤 메시지의 토픽이 $[t_0, t_1, …, t_k]$일 때, 루트 노드
*를 포함한 각 $t_0, t_1, …, t_k$노드의 모든 엔트리에 메시지를 전송한다.
이 알고리즘을 최적화하기위해서는 토픽을 Key로, Subscriber 집합을 Value로 하는 인덱스와 그것의 역인덱스가 필요하다.
// https://github.com/boxcolli/go-transistor/blob/main/index/index.go
// Index node
type Inode struct {
Prev *Inode
Token string
Eset map[Entry]bool
Next map[string]*Inode
}
// Inversed index node
type Vnode struct {
Prev *Vnode
Token string
Pair *Inode
Next map[string]*Vnode
}
Prev: 알고리즘 구현을 쉽게 만들어주는 부모 노드 포인터Token: 토픽의 스트링 리스트 중 노드에 할당된 하나의 스트링Eset: Subscriber 집합Pair: Vnode에서 Inode를 가리키는 포인터Next: 자식 노드 포인터 집합
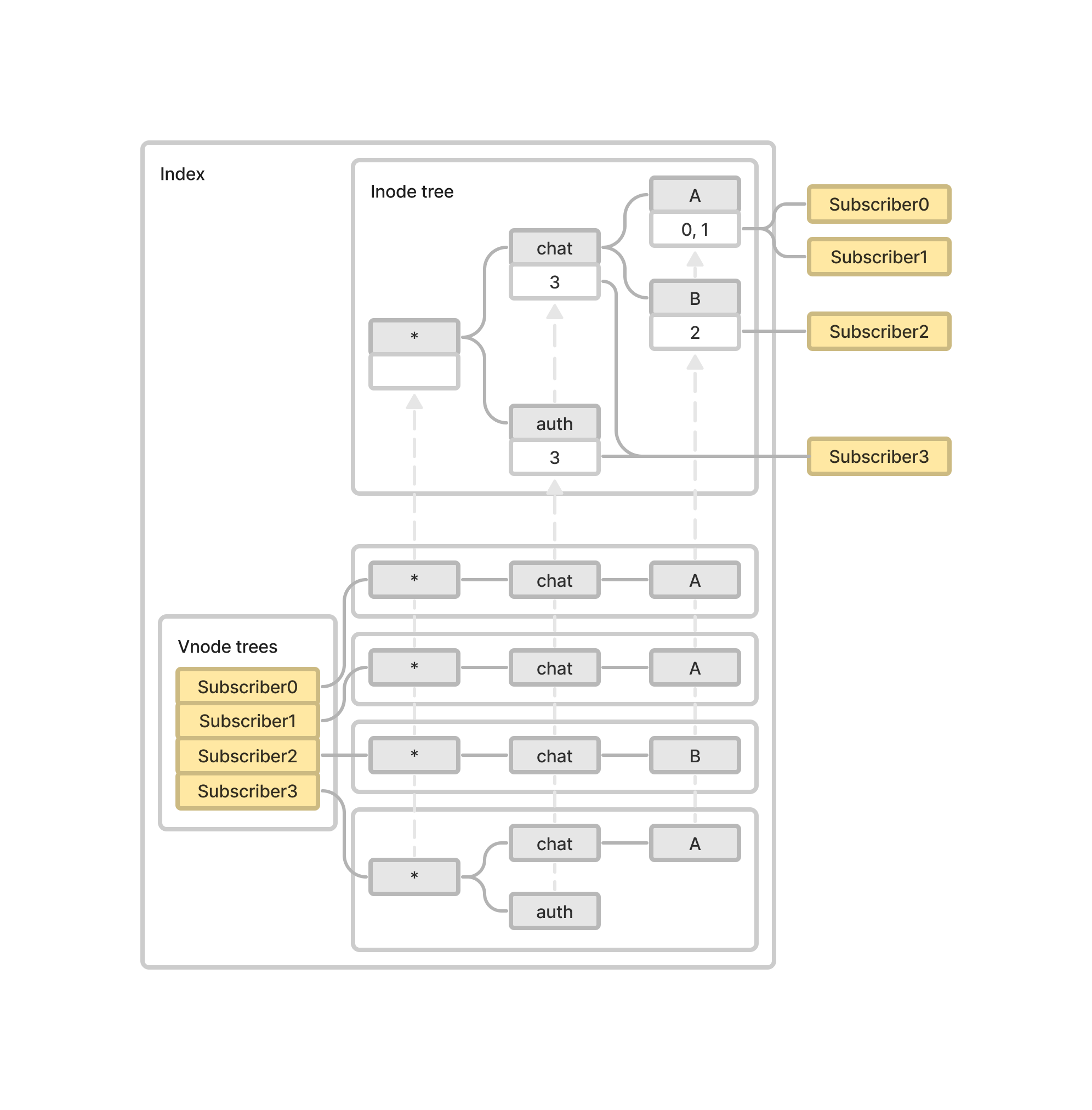
최종 인덱스의 자료 구조 예시이다.
Base
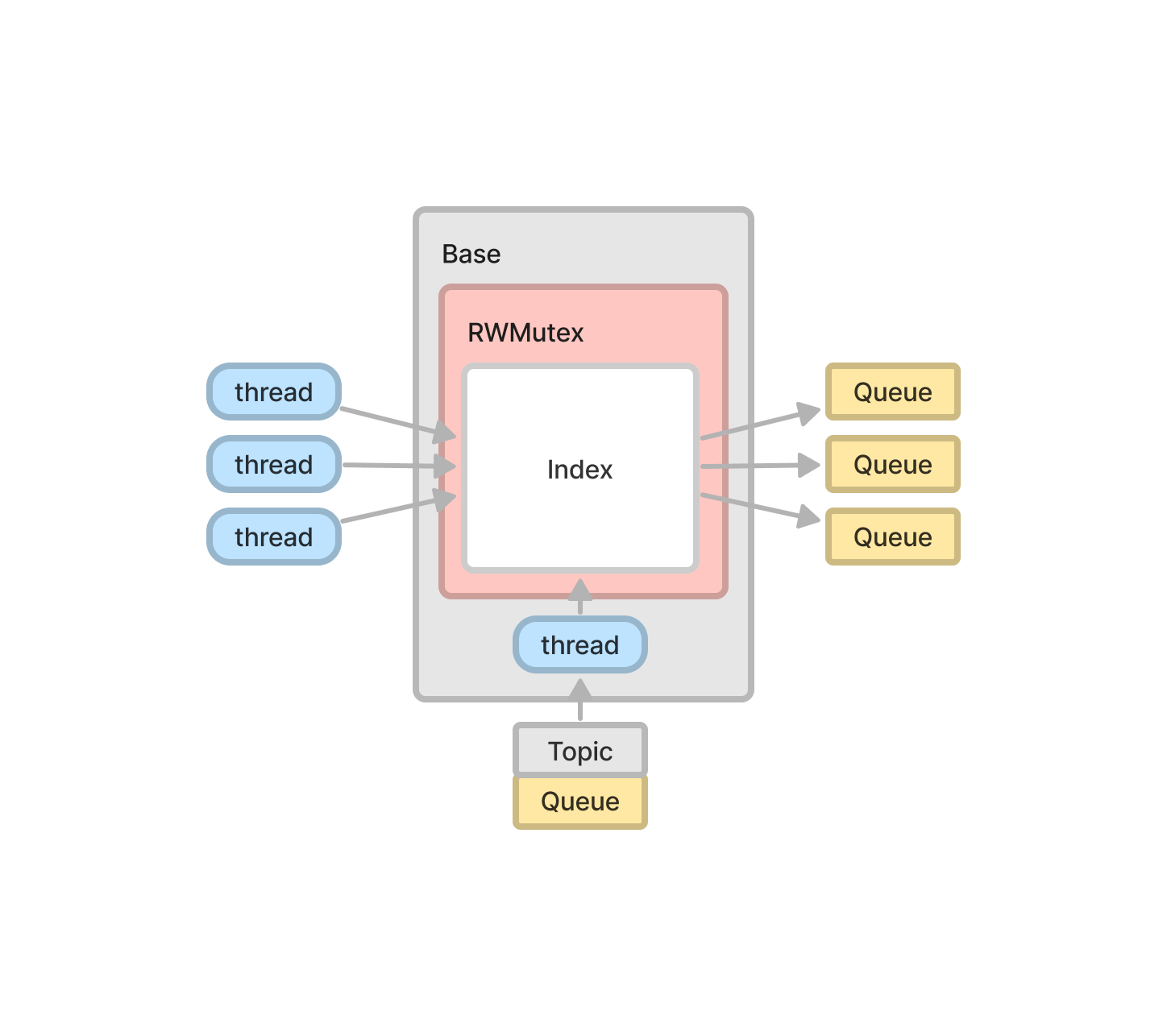
Base의 역할은 Subscription을 추가하고 제거하는 것이다. 그러나 동시에 여러 스레드가 인덱스에 접근하고있기 때문에, Mutex Lock에 의한 지연시간이 발생할 수 있다.
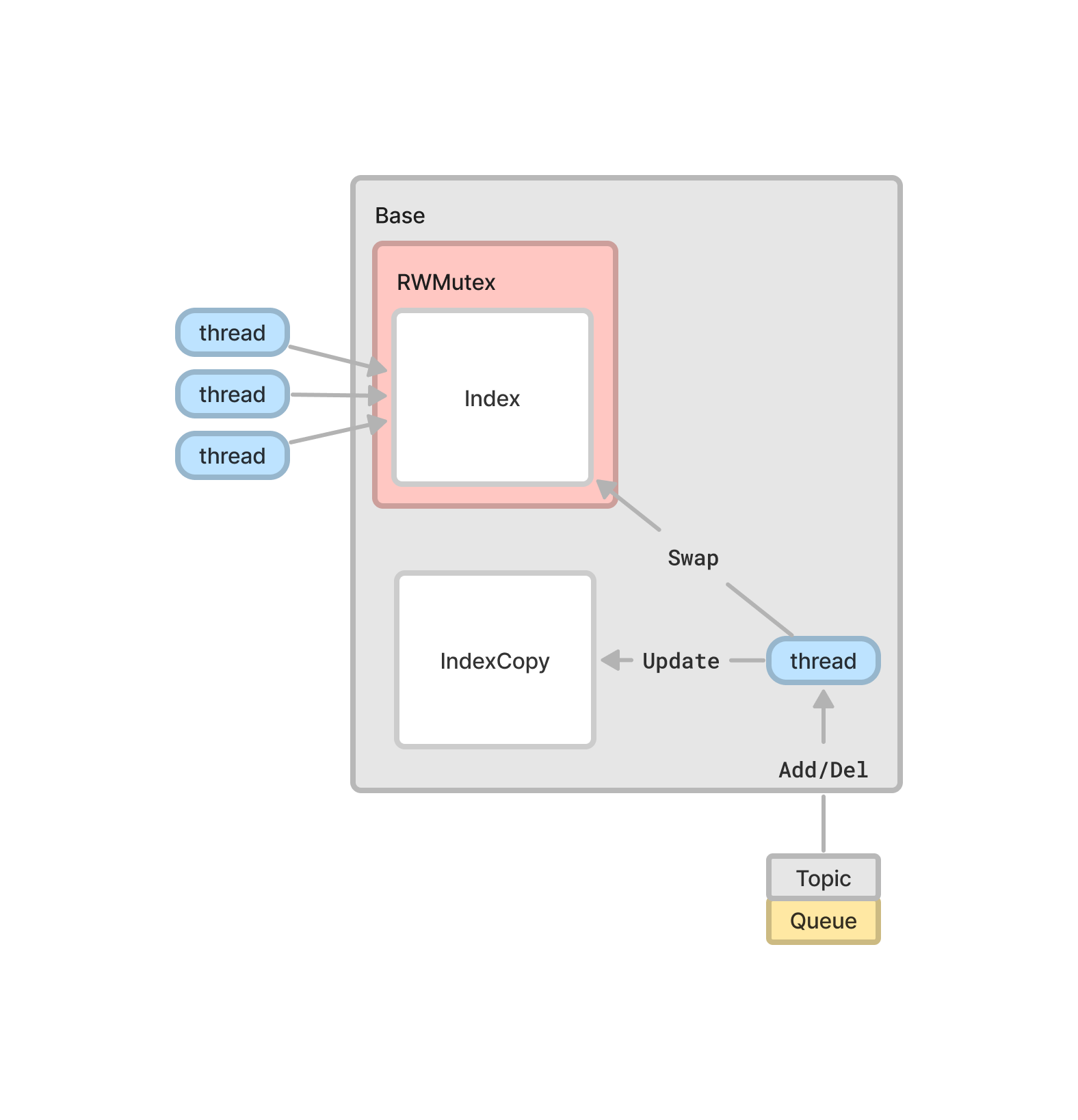
인덱스 복제본을 만들어서 업데이트를 하고 원래 인덱스와 스왑해서 다시 똑같은 업데이트를 하는 방법으로 Collector에서의 접근 대기 시간을 최소화할 수 있다. 이때 무의미한 업데이트에 대해 Mutex Lock이 발생하는 것을 막기 위해 인덱스 복제본은 Request Validity를 반환한다.
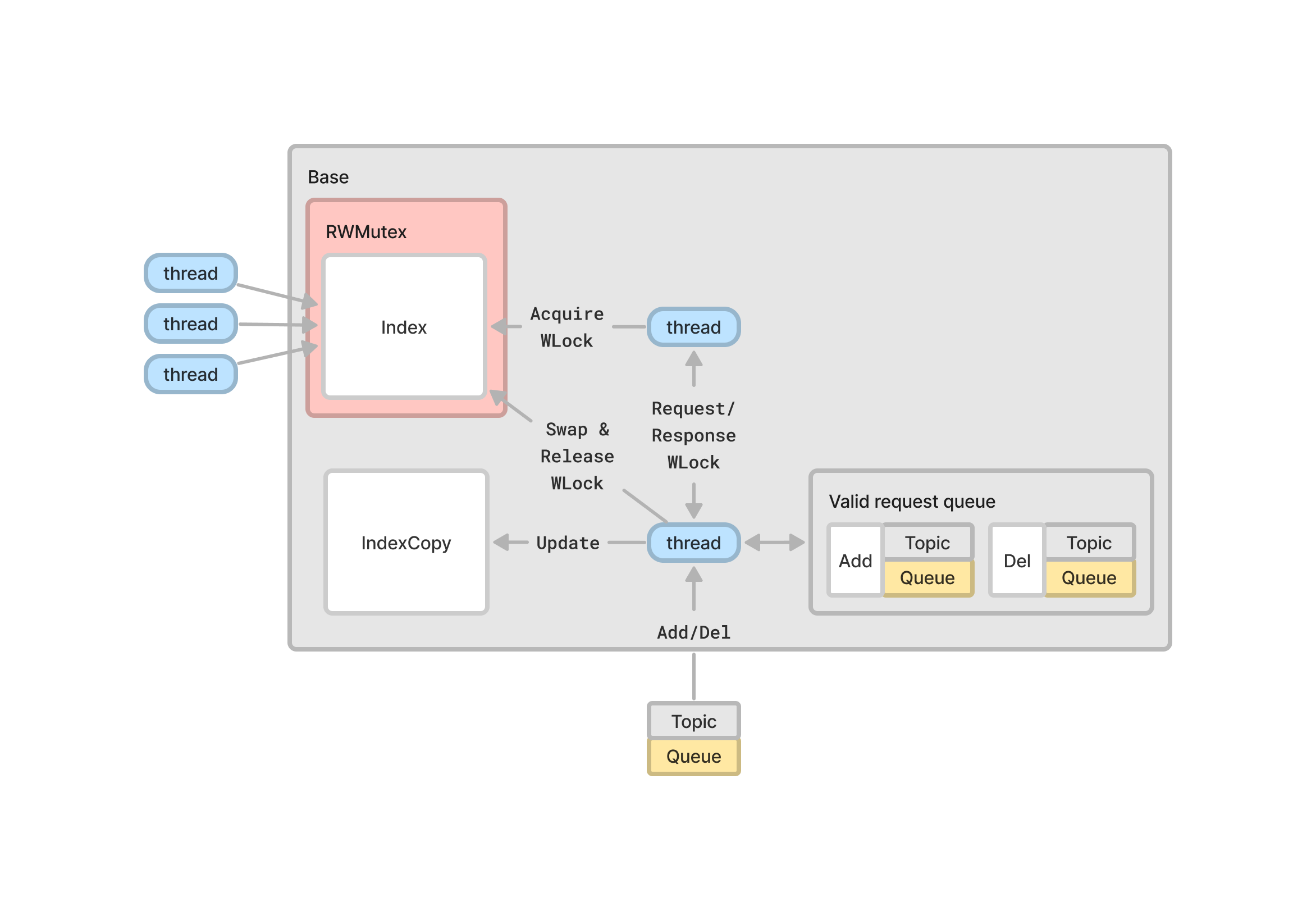
Writer Lock은 모든 Reader Lock이 반환되어야 이루어진다. 따라서 스레드가 장시간 Sleep 상태에 빠질 수 있다. 이것을 방지하기위해 또다른 스레드에게 Writer Lock을 맡기고, 그동안 최대한 많은 업데이트를 처리한다. 이 방법은 인덱스 트리가 크고 복잡한 상황에서 더욱 효과적이다.
Scalability and Auto Discovery
 트랜지스터 서버는 동시에 여러 서버와 연결할 수 있다.
트랜지스터 서버는 동시에 여러 서버와 연결할 수 있다.
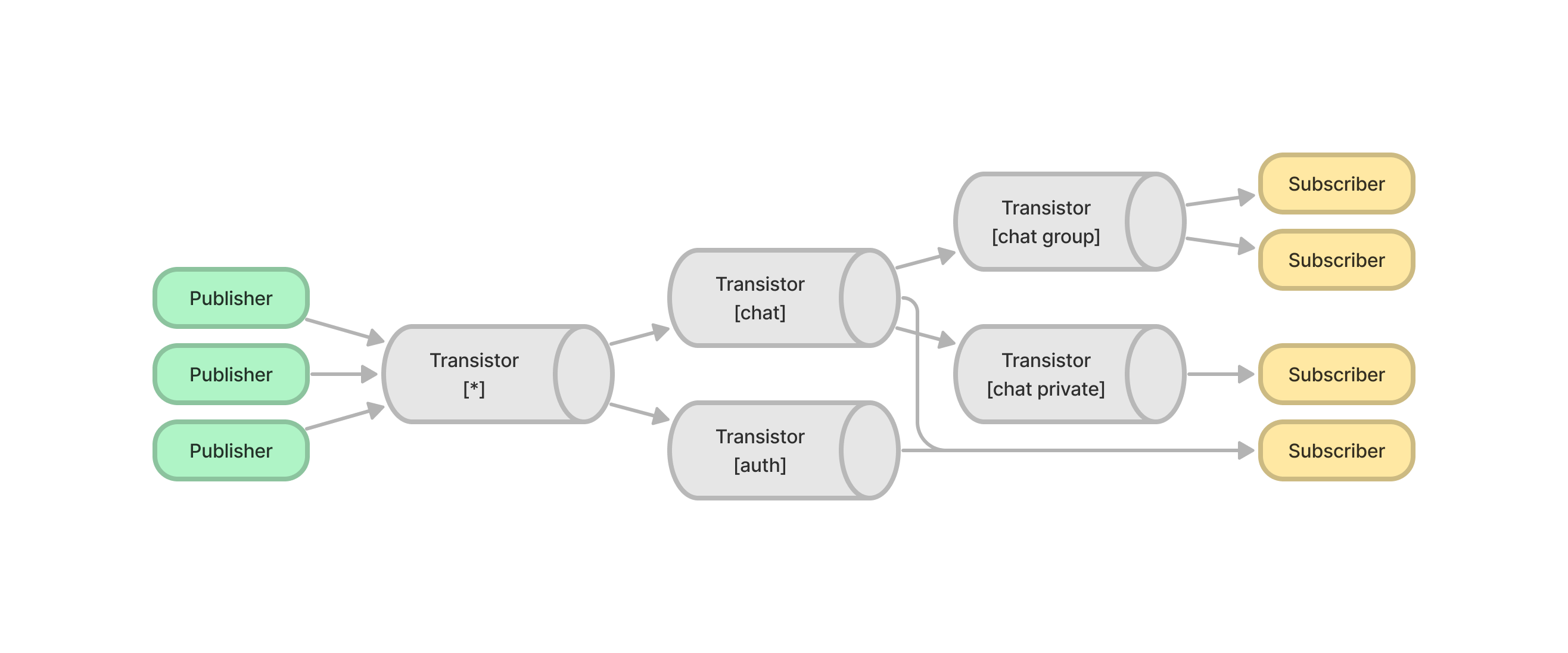 동시에 여러 트랜지스터를 연결하면 메시지를 복제하고, 네트워크 Bandwidth를 더 크게 쓸 수 있다.
동시에 여러 트랜지스터를 연결하면 메시지를 복제하고, 네트워크 Bandwidth를 더 크게 쓸 수 있다.
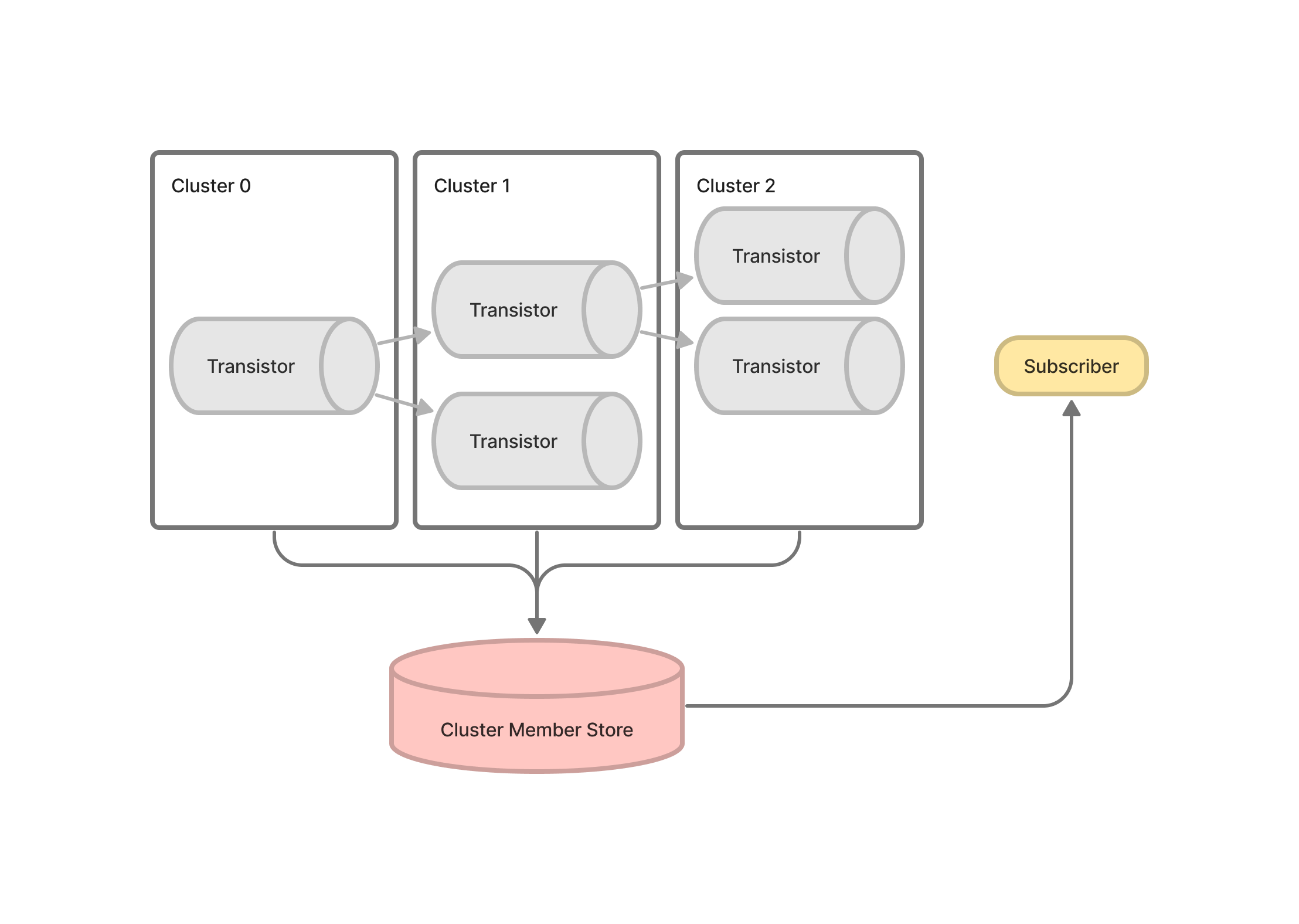 트랜지스터의 각 계층을 클러스터로 간주하여 Cluster Member Store에 자신의 네트워크 주소를 게시하면 Subscriber가 필요한 계층의 클러스터에 스스로 구독할 수 있다. Cluster Member Store로 쓸 DB는 Keyspace Stream을 지원하는 Redis 또는 etcd가 적합할 것이다. (현재 미구현)
트랜지스터의 각 계층을 클러스터로 간주하여 Cluster Member Store에 자신의 네트워크 주소를 게시하면 Subscriber가 필요한 계층의 클러스터에 스스로 구독할 수 있다. Cluster Member Store로 쓸 DB는 Keyspace Stream을 지원하는 Redis 또는 etcd가 적합할 것이다. (현재 미구현)
Implementation
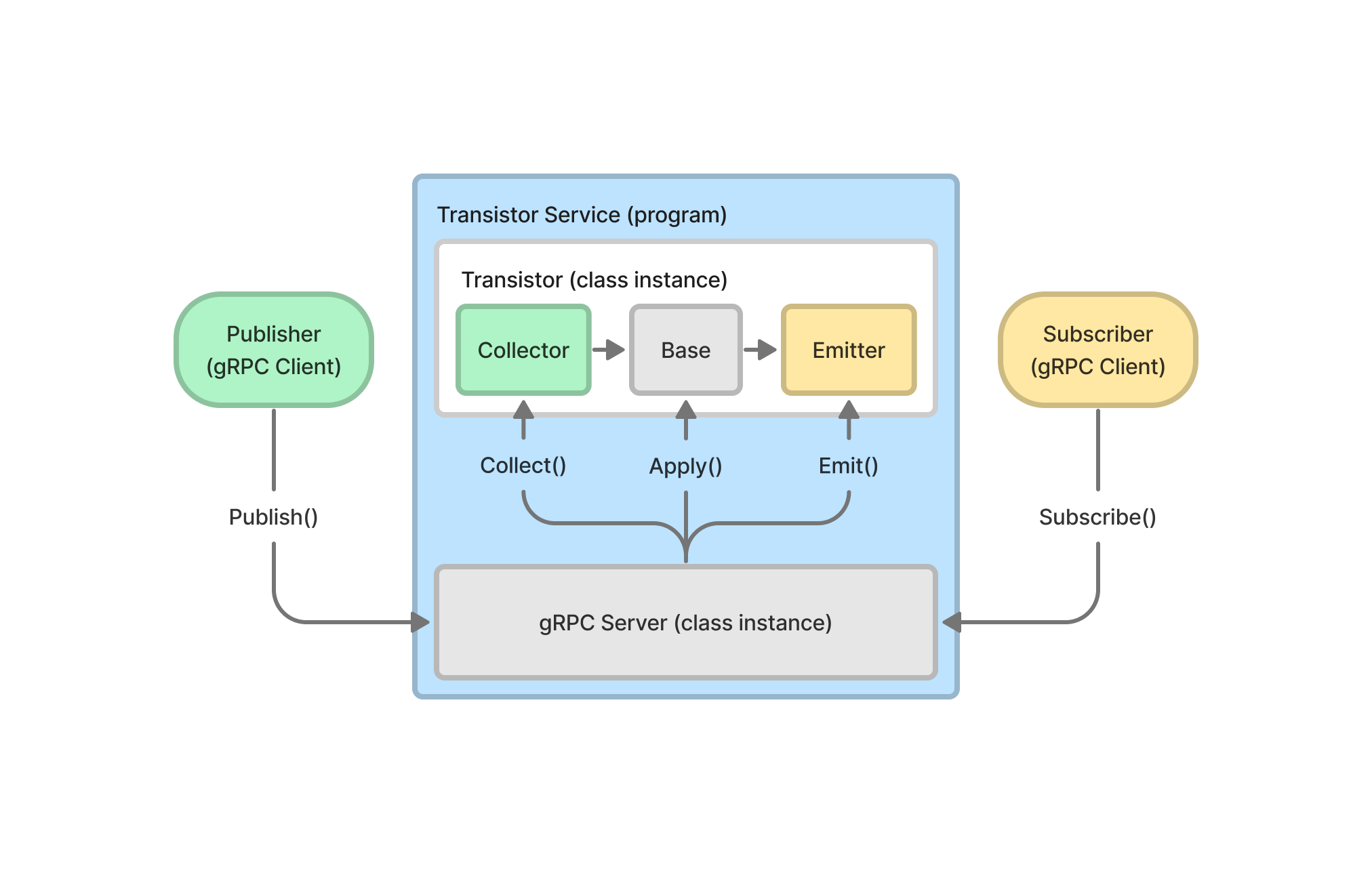 구현에는 Go언어와 gRPC 네트워크 프레임워크를 사용했다. Go언어는 성능과 생산성이 뛰어나기 때문에 과제의 난이도와 한정된 시간이라는 조건에 가장 적합했고, gRPC는 성능이 뛰어나면서 대중적이기 때문에 프로젝트의 사용성을 높여줄 수 있을 것 같아 선택했다.
구현에는 Go언어와 gRPC 네트워크 프레임워크를 사용했다. Go언어는 성능과 생산성이 뛰어나기 때문에 과제의 난이도와 한정된 시간이라는 조건에 가장 적합했고, gRPC는 성능이 뛰어나면서 대중적이기 때문에 프로젝트의 사용성을 높여줄 수 있을 것 같아 선택했다.
Performance
테스트에 사용된 서버 인스턴스는 Google Kubernetes Engine에서 실행되었다.
트랜지스터 내부에서 별도의 스레드를 통해 지표를 측정하고, 로컬 CLI에서 쿠버네티스에서 실행중인 트랜지스터와 gRPC로 연결하여 모니터링했다.
Publisher는 Sleep 없는 무한 루프로 메시지를 생성한다. 트랜지스터 내부의 메시지 큐는 크기가 10이다. 즉 Publisher는 빠른 속도로 트랜지스터의 메시지 큐 공간을 고갈시키고, 네트워크의 버퍼를 전부 채운 뒤, 메시지가 큐에서 제거될 때마다 즉시 새로운 메시지를 보내게 된다.
메시지 크기는 30Byte이다.
모든 테스트에서 트랜지스터가 사용한 RAM은 20MB를 넘지 못했다.
Single Transistor and Single Subscriber
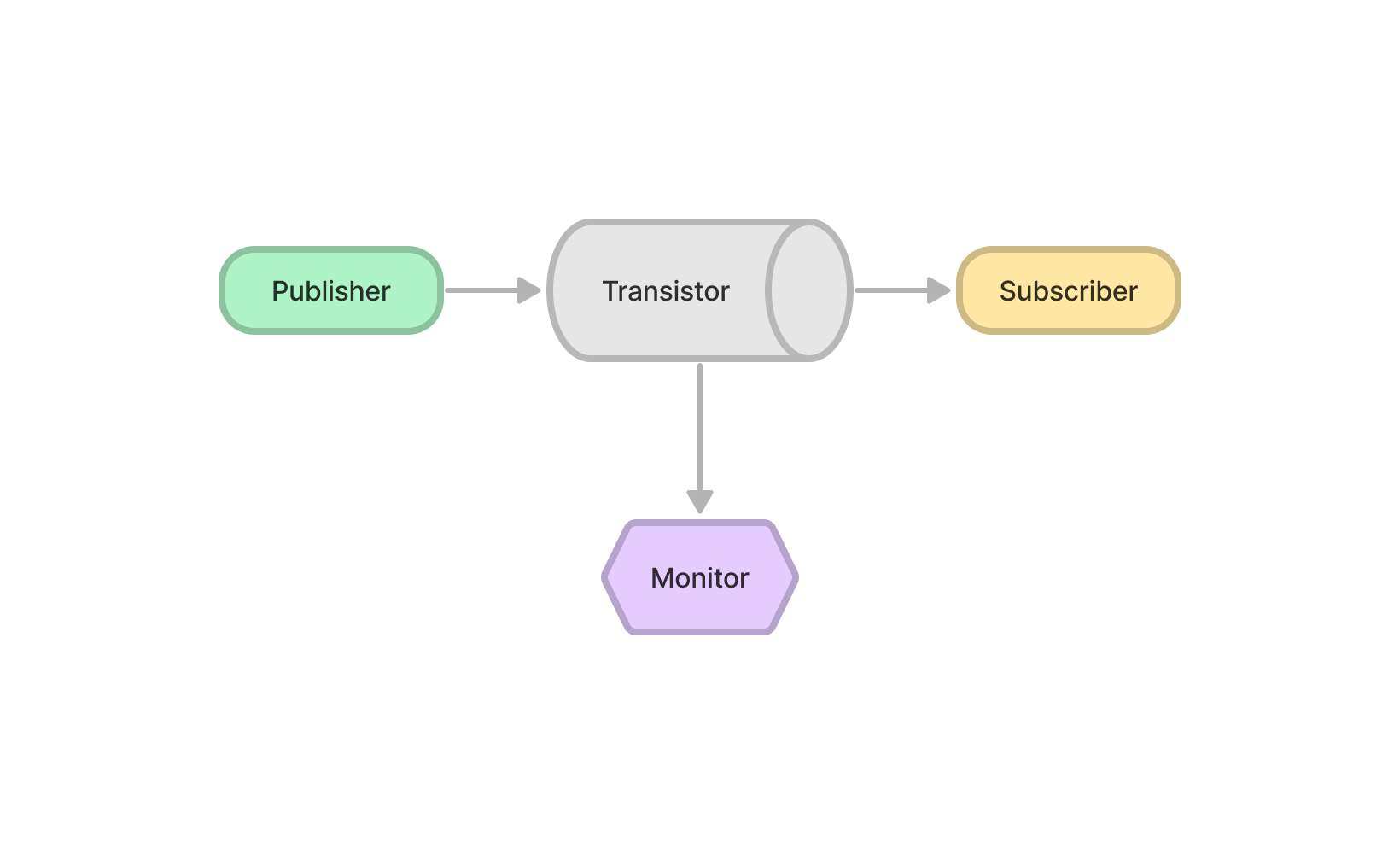
| core | Msg/sec | Msg/sec*core |
|---|---|---|
| 0.5 | 57,400 | 114,800 |
| 1.0 | 185,667 | * 185,667 |
| 1.5 | 274,000 | 182,667 |
| 2.0 | 275,667 | 137,833 |
| 2.5 | 317,000 | 126,800 |
| 3.0 | 311,333 | 103,778 |
| 8.0 | * 391,000 | 48,875 |
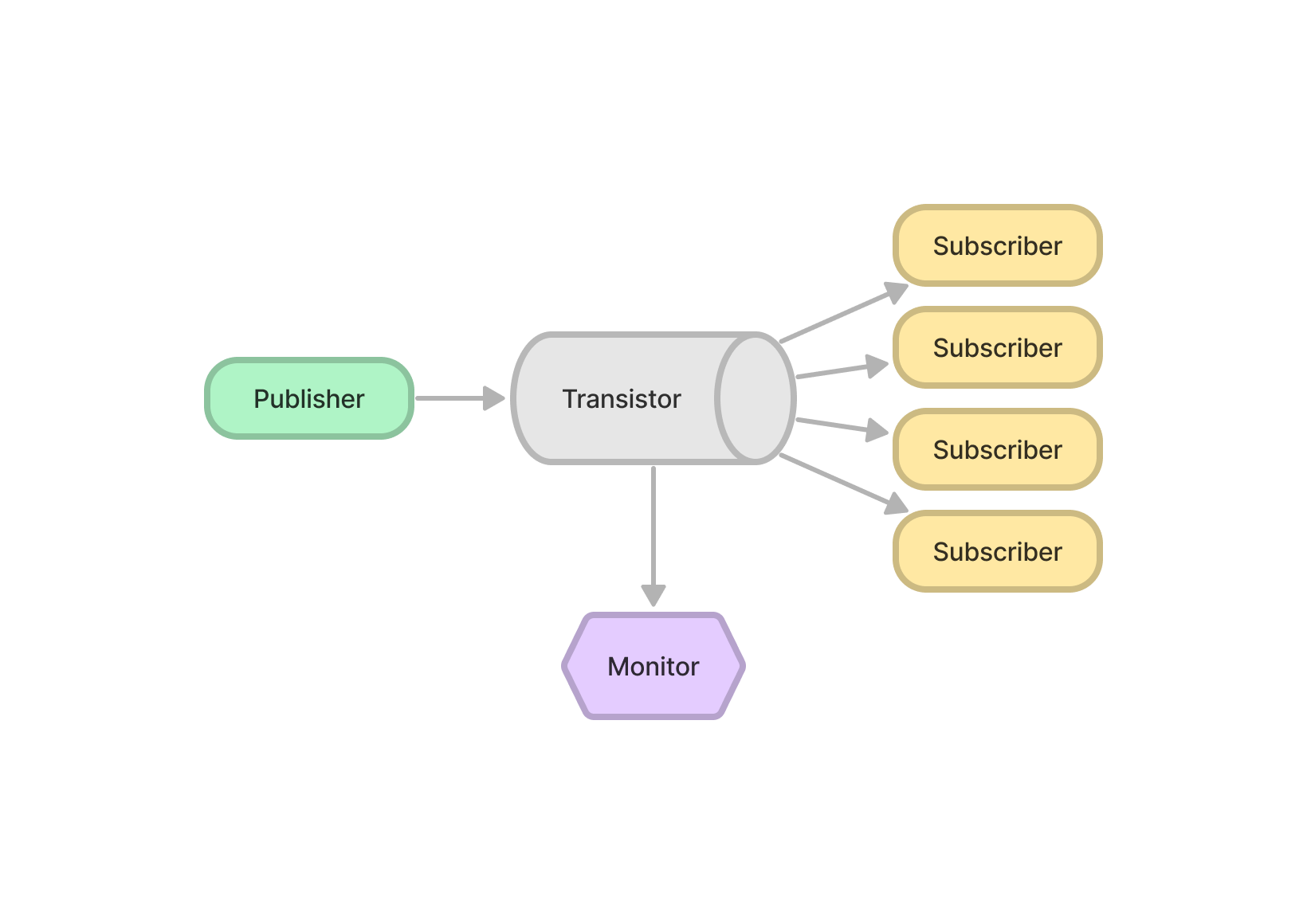
Single Transistor and Multiple Subscribers
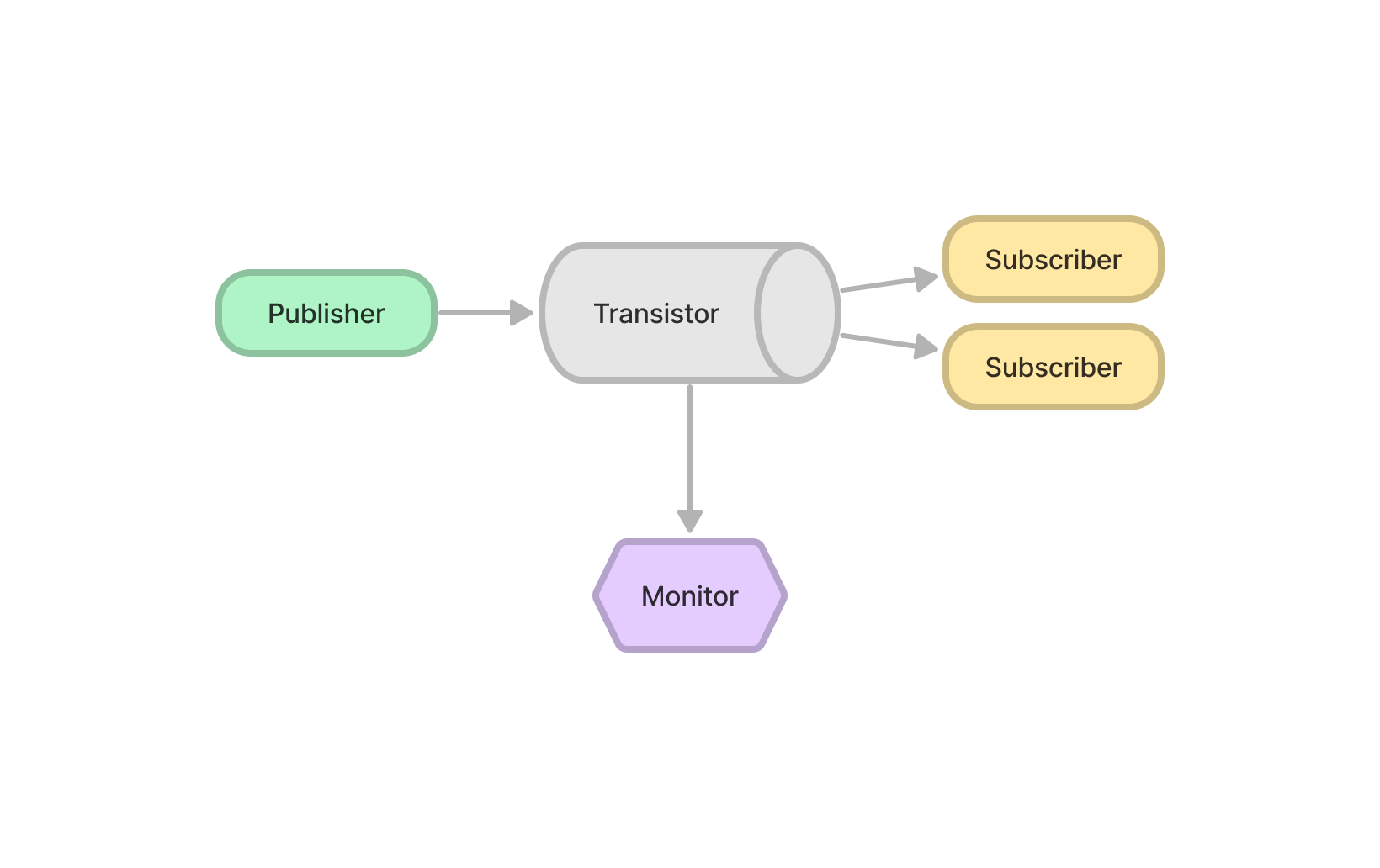 |
 |
|---|---|
| 2 Subscribers | 4 Subscribers |
| #sub | core | Total Msg/sec | Total Msg/sec*core |
|---|---|---|---|
| 2 | 3 | 162,750 | 54,250 |
| 2 | 6 | 170,010 | 28,335 |
| 2 | 9 | 184,530 | 20,503 |
| 4 | 3 | 238,300 | * 79,433 |
| 4 | 6 | 250,600 | 41,767 |
| 4 | 9 | * 259,812 | 28,868 |
Multiple Transistors and Multiple Subscribers
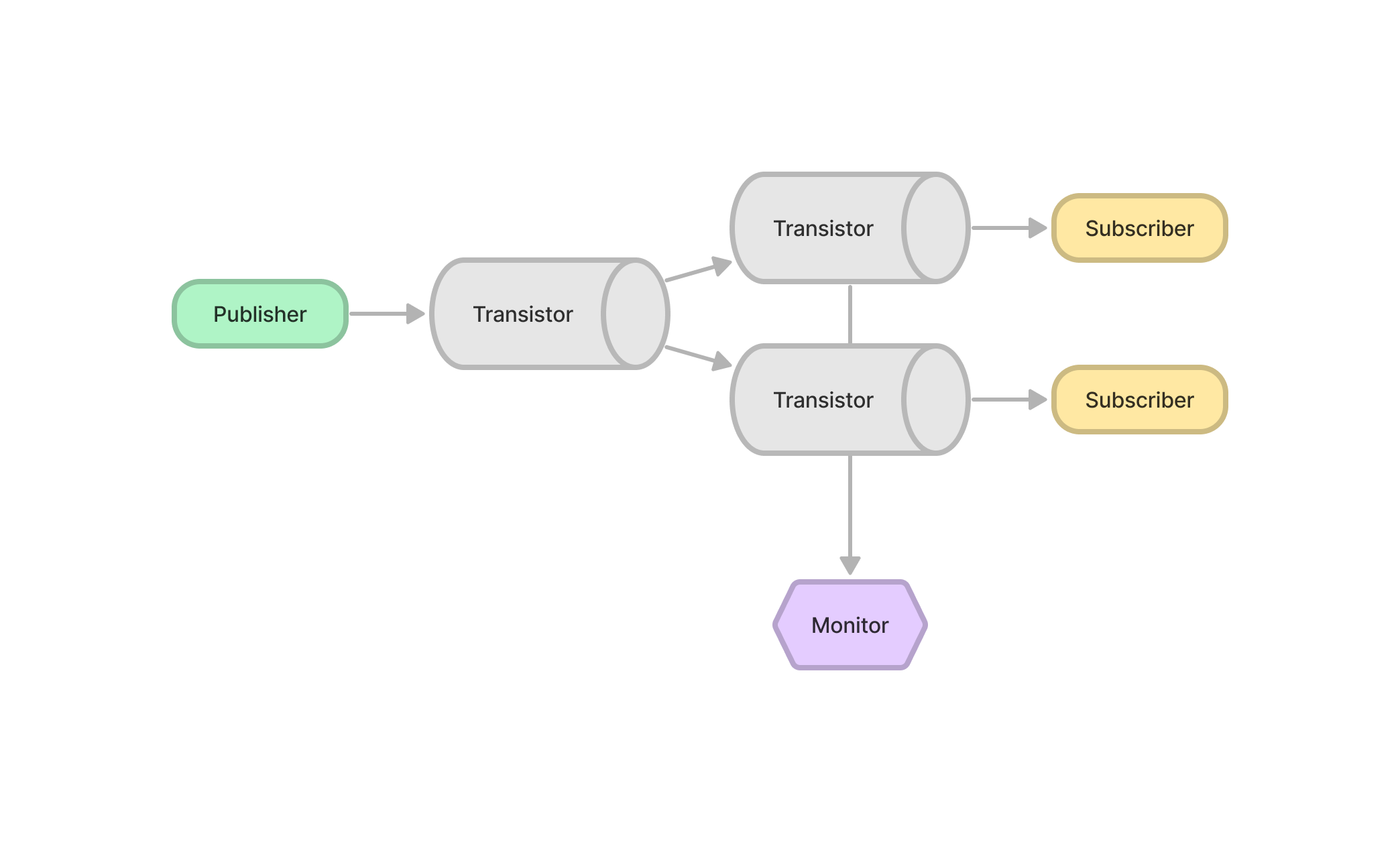 |
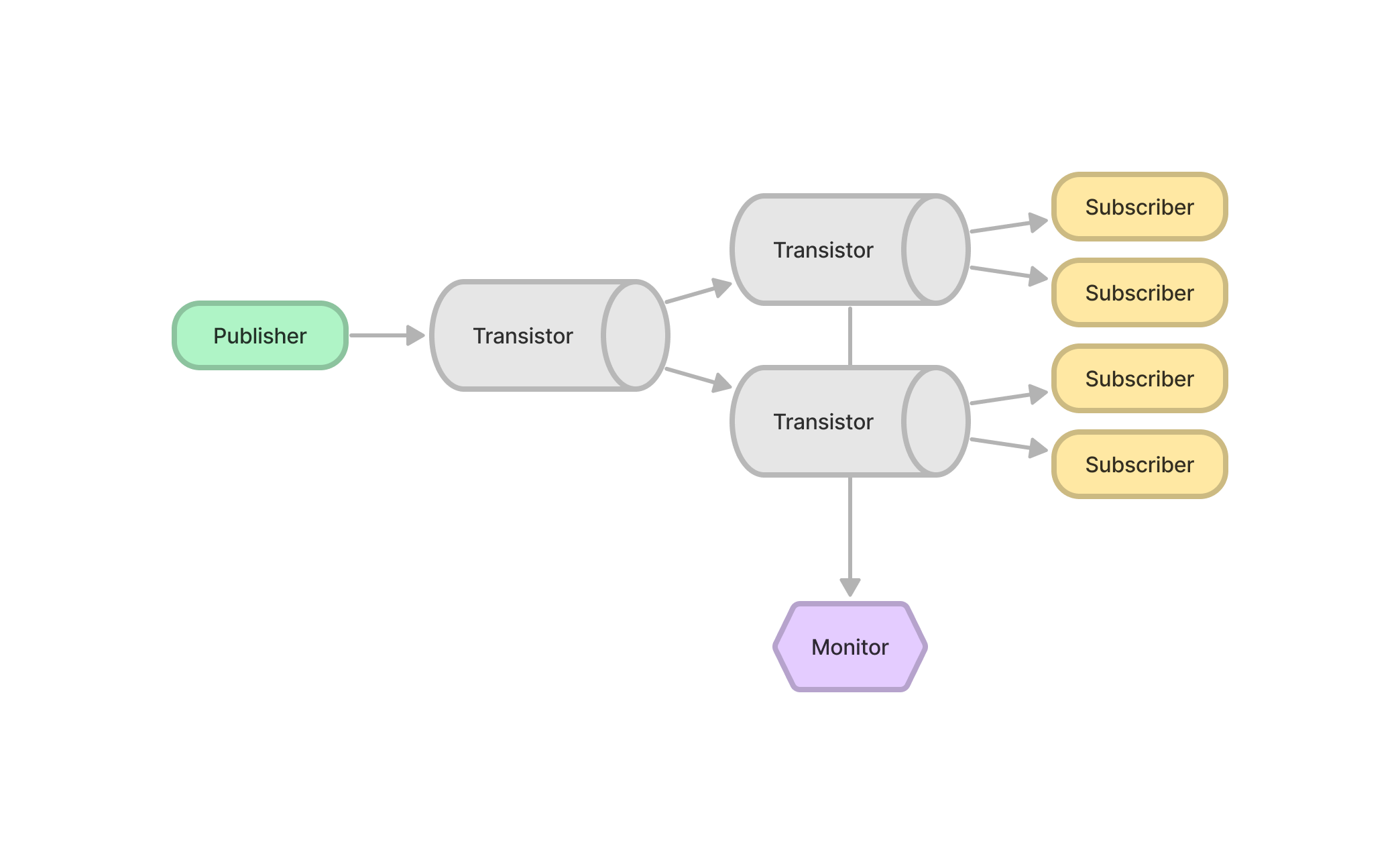 |
|---|---|
| 3 Transistors w 2 Subscribers | 3 Transistors w 4 Subscribers |
| #sub | core | Total Msg/sec | Total Msg/sec*core |
|---|---|---|---|
| 2 | 3 | 59,043 | 19,681 |
| 2 | 6 | 123,261 | 20,544 |
| 2 | 9 | 183,134 | 20,348 |
| 4 | 3 | 115,022 | 38,341 |
| 4 | 6 | 255,440 | * 42,573 |
| 4 | 9 | * 358,444 | 39,827 |
Application
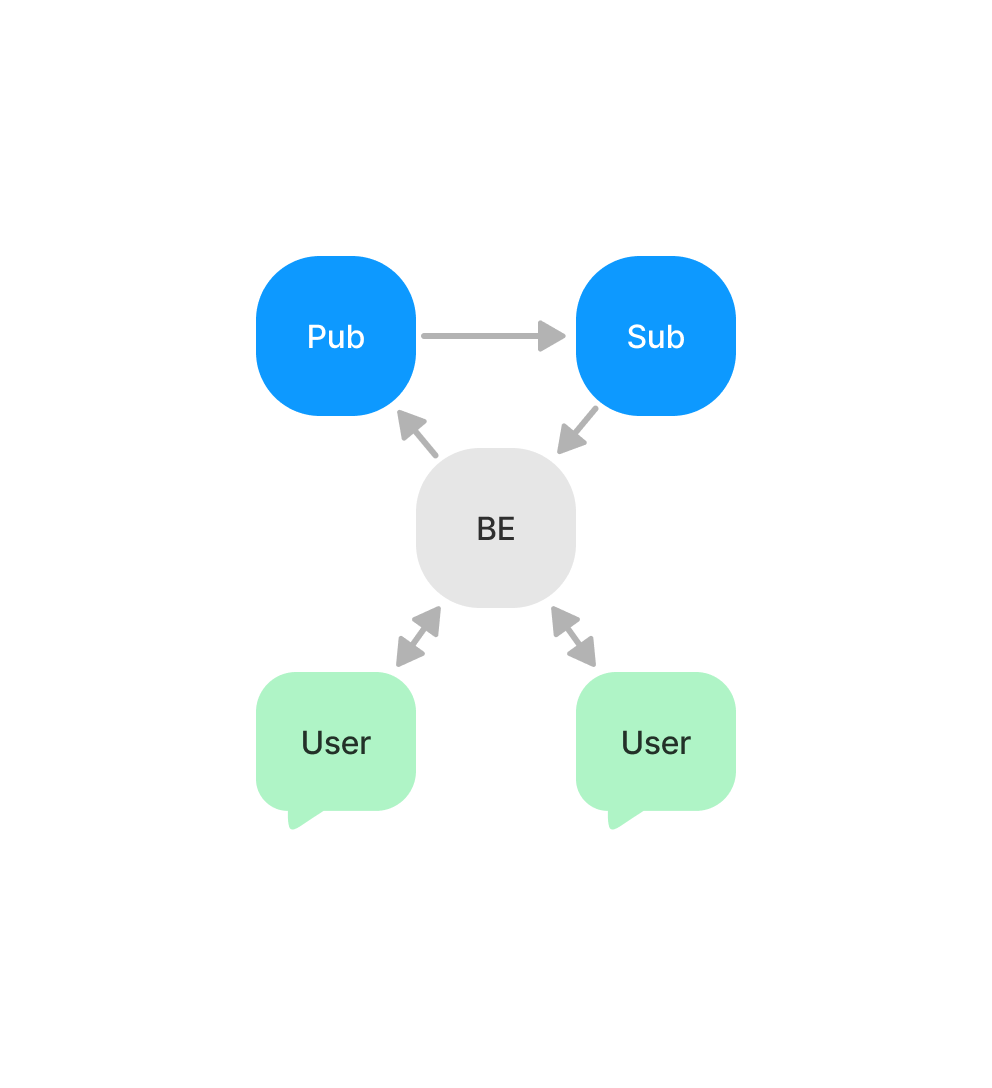 트랜지스터를 이용한 채팅 앱 서비스는 DB없이 간단하게 구현했다.
트랜지스터를 이용한 채팅 앱 서비스는 DB없이 간단하게 구현했다.
- 채팅방 입장 & 메시지 받기:
[GET] /chat/{chat_id}/ws
{
"message": {
"message_id": "UUIDv7",
"username": "bob",
"content": "hello",
"created_at": "2006-01-02 15:04:05"
}
}
- 메시지 생성하기:
[POST] /chat/{chat_id}/message
Header:
"x-username": "john"
Body:
{
"content": "hello"
}
모바일 앱 프로그래밍은 다른 프로젝트 팀원이 맡고, 나는 API 및 백엔드, 트랜지스터의 도커 이미지를 맡았다. 백엔드는 Go Fiber를 사용했다.
 |
 |
|---|---|
| Home page | Chat page |